Migration nach Microsoft Fabric
- Dirk Müller

- 20. Jan.
- 9 Min. Lesezeit
Aktualisiert: 28. Jan.
Am Anfang klingt es simpel: Daten raus aus Synapse oder SQL Server, rein in Fabric, fertig. In der Realität ist „Migration nach Microsoft Fabric“ selten ein reines Kopierprojekt, weil du nicht nur Daten bewegst, sondern Verantwortung: Workloads, SLAs, Security, Kostenlogik, und vor allem die Frage, wer nachher „die Wahrheit“ besitzt.
Die gute Nachricht: Fabric gibt dir mehrere saubere Pfade – wenn du früh entscheidest, welchen du wirklich brauchst. In diesem Beitrag bekommst du genau dafür eine pragmatische Landkarte: zwei Hauptwege (Synapse dedicated SQL pool und SQL Server) plus die typischen Stolpersteine, die dir sonst erst kurz vor dem Cutover auffallen.
Zum Warmwerden: Wenn du nach dem Lesen nur eine Sache mitnimmst, dann diese: Ziel-Architektur zuerst, Tooling danach. Alles andere ist teure Improvisation.
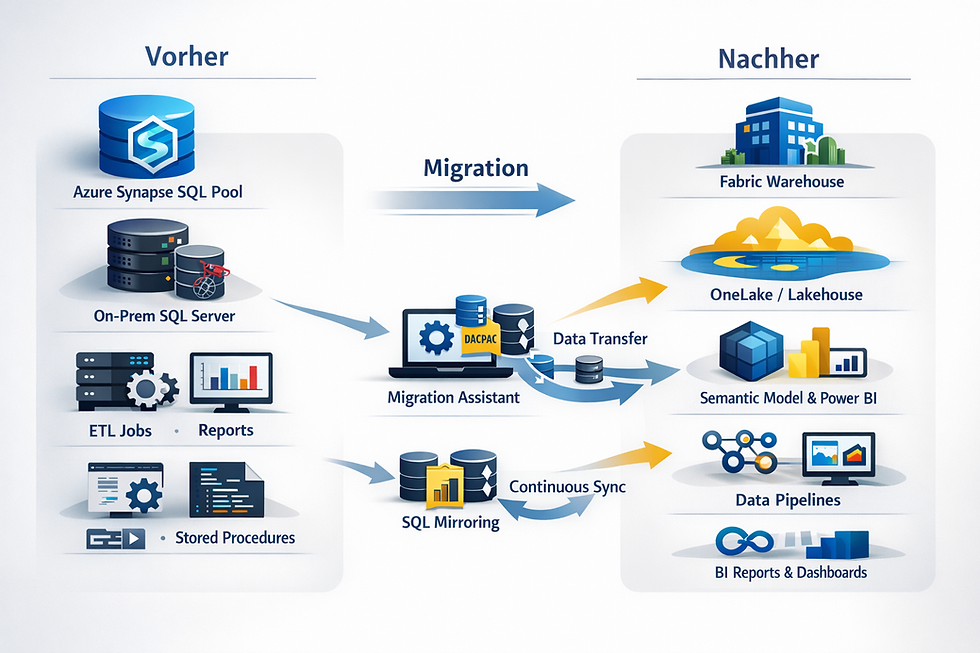
Wohin migrieren: Warehouse, OneLake und die SQL-Welt in Fabric
Bevor du über „wie migrieren wir?“ sprichst, brauchst du ein klares „wohin genau?“. Fabric ist eine Plattform mit mehreren Zielobjekten, die sich ähnlich anfühlen können, aber sehr unterschiedliche Konsequenzen haben.
Für Migrationen aus Synapse und SQL Server landest du typischerweise in einer dieser Denkwelten:
Fabric Warehouse: wenn du analytische SQL-Workloads und DWH-Patterns sauber abbilden willst. Das ist der naheliegende Zielpunkt für Synapse dedicated SQL pool-Migrationen.
OneLake/Lakehouse als Datenrückgrat: wenn du Daten domänenübergreifend bereitstellen willst, ohne alles sofort umzubauen. Shortcuts und Mirroring sind hier die Hebel.
SQL in Fabric (je nach Szenario): wenn du eher aus einer operationalen SQL-Welt kommst und einen kontrollierten Übergang suchst – mit klaren Produktgrenzen.
Der wichtigste Abschluss dieser Einordnung: Du solltest nicht SQL sehen und automatisch denken, dass es sich wie dein SQL Server von 2016 anfühlt. Fabric hat unterschiedliche Engines und Limitierungen – und die wirken nicht irgendwann, sondern genau dann, wenn du im Projekt unter Zeitdruck gerätst. Daher ist eine Migrationsstrategie wichtig, die nicht vom Zufall lebt.
Drei Migrationsmuster, die in Fabric wirklich funktionieren
Damit du nicht zwischen Tools und Features hin- und herspringst, hilft eine einfache Einteilung. In Fabric laufen die meisten erfolgreichen Migrationen auf eines dieser Muster hinaus:
Parallelbetrieb mit Bridge Du lässt die Quelle erstmal Quelle bleiben, bringst Daten kontinuierlich nach Fabric und schwenkst Konsumenten später um. Für SQL Server ist Mirroring häufig genau diese Brücke.
Re-Platforming mit Assistenz Du nimmst in Kauf, dass nicht alles 1:1 ist, willst aber einen geführten Weg. Für Synapse dedicated SQL pool ist der Migration Assistant (DACPAC-basiert) der zentrale Pfad.
Schrittweise Modernisierung ohne Copy-Orgien Du bindest Daten über OneLake so an, dass Teams schon arbeiten können, während du strukturell nachziehst. Shortcuts sind dafür der pragmatische Trick.
Der Abschluss hier ist wichtig: Du musst dich nicht für genau ein Muster für immer entscheiden. Aber du solltest pro Datenprodukt (z. B. Finance DWH, Sales Mart, Operational DB) ein klares Leitmuster wählen. Und genau dafür kommt jetzt die Vorarbeit.
Vorbereitung: Ohne diese Basis wird Migration zum Glücksspiel
Jetzt kommt der Teil, den keiner wirklich spannend findet – der aber später dein Projekt rettet. Migration nach Microsoft Fabric funktioniert dann gut, wenn du vor dem ersten Copy-Lauf die harten Fakten klärst.
Abhängigkeiten-Inventar (nicht nur Tabellen zählen)
Schreibe dir zusammen, wer alles an deiner Quelle hängt:
Reports, Semantic Models, Excel-Power-User, APIs
ETL/ELT-Jobs, Stored Procedures, Views, Funktionen
Security: Rollen, Masking, Row-Level Security, Service Accounts
Definition von fertig migriert
Lege fest, wie du Gleichheit beweist:
Rowcounts (pro Tabelle/Partition)
Fachliche Kontrollabfragen (Totals, Perioden, Ausreißer)
Report-Vergleich (Key-KPIs, nicht jeder Pixel)
Region & Kapazität als Go/No-Go
Ein klassischer Fabric-Fail ist nicht Technik, sondern Geografie und Kapazität: bestimmte Verbindungen/Workflows sind an Regionen gebunden. Wenn du das erst am Ende merkst, wird aus Migration schnell politisches Krisenmanagement.
Netzwerk und Zugriff (vor allem bei SQL Server)
Sobald SQL Server on-prem oder in einer geschützten Zone sitzt, ist „wir spiegeln das mal eben“ vorbei. Dann reden wir über Gateway/Firewall/Identitäten – also echte Infrastrukturarbeit.
Wenn diese Vorbereitung steht, wird die eigentliche Migration planbar. Und planbar ist in Projekten meistens gleichbedeutend mit bezahlbar. Jetzt gehen wir in die zwei Pfade.
Pfad 1: Synapse dedicated SQL pool nach Fabric Warehouse
Wenn dein Startpunkt Azure Synapse Analytics dedicated SQL pool ist, ist die Versuchung groß, auf „Lift & Shift“ zu hoffen. Der bessere Blick ist: Du machst ein Re-Platforming mit klarer Tool-Unterstützung – und du profitierst davon, wenn du Inkompatibilitäten früh als Liste bekommst statt spät als Incident.
Microsoft hat für den Umzug von Synapse dedicated SQL pool ins Fabric Warehouse einen empfohlenen Prozess: erst Schema via DACPAC überführen und prüfen, dann die Daten migrieren – unterstützt durch den Microsoft Migration Assistant.
Behandle den Synapse-Umzug wie eine kontrollierte Modernisierung. Dann ist jede Anpassung eine bewusste Entscheidung – nicht ein hektischer Hotfix am Freitagabend.
DACPAC als Dreh- und Angelpunkt: Sauber exportieren, migrieren
Für den Warehouse-Pfad ist DACPAC der zentrale Transportbehälter: Er enthält Objekt-Metadaten, die der Migration Assistant auswertet und überführt. Worauf du in der Realität achten solltest:
DACPAC-Export ist ein Qualitätsfilter: Wenn dein Schema heute schon unsauber ist (inkonsistente Schemas, alte Objekte, halbgenutzte Staging-Tabellen), migrierst du sonst den Müll einfach mit.
Objektarten bewusst prüfen: Der Migration Assistant nennt klar, welche Objektklassen er abdeckt (Tabellen, Views, Funktionen, Stored Procedures, Security-Objekte wie Rollen/Permissions, Dynamic Data Masking).
Dein Ziel ist Wiederholbarkeit: Ein Export, der einmal klappt, ist nett. Ein Export, der als Prozess klappt, ist Gold wert (für Dev/Test/Prod).
Wenn dein DACPAC-Flow reproduzierbar ist, hast du die Grundlage für ein Migrationstempo, das du steuern kannst. Dann lohnt sich der nächste Schritt: Migration Assistant nicht als Zauberstab, sondern als strukturiertes Prüfwerkzeug zu nutzen.
Nicht nur migrieren, sondern Inkompatibilitäten bewusst abarbeiten
Der Migration Assistant ist in dieser Story nicht einfach ein Copy-Button. Er ist dein geführter Ablauf, um Schema zu konvertieren, Probleme sichtbar zu machen und dich nicht im Blindflug ins Ziel zu tragen. Microsoft beschreibt ihn als Migrationserfahrung, die dedicated SQL pools (und auch andere SQL-Plattformen) in Richtung Fabric Warehouse überführt.
Pragmatische „Lessons Learned“ aus diesem Schritt:
Plane eine Fix-Schleife ein: Migration heißt hier oft „migrieren → Findings → korrigieren → nochmal“. Wenn du das zeitlich nicht einplanst, verschiebst du die Arbeit nur nach hinten.
Nutze Findings als Architektur-Diskussion: Manche „Fehler“ sind keine Fehler, sondern Hinweise, dass du Dinge früher hättest standardisieren sollen (Namenskonventionen, Schematrennung, Ownership).
Dokumentiere Entscheidungen: Wenn du Objekt A anpasst, weil Fabric es anders erwartet, schreib auf warum. Das wird sonst später zu „wer hat das kaputt gemacht?“.
Nach dem Schema kommt der Teil, der gerne unterschätzt wird: Daten. Und Datenmigration ist weniger Tooling – mehr Taktik.
Daten übernehmen: Bulk zuerst, kontrollierte Deltas bis zum Cutover
Beim Datenumzug gewinnst du nicht durch Heldentaten, sondern durch saubere Sequenzen. In Fabric ist ein typischer Baustein dafür der Copy job als praktisches Werkzeug für Datenbewegung.
Ein bewährtes Vorgehen:
Bulk-Load als Fundament: Du bringst den Großteil der Daten einmal rüber, möglichst in einem definierten Wartungsfenster.
Delta-Strategie bis Cutover: Danach nur noch kontrollierte Nachläufe (je nach Quelle und Logik), damit du am Umschalttag nicht „alles auf einmal“ machen musst.
Validierung in Wellen: Nicht bis zum Schluss warten. Nach Bulk schon fachlich gegenprüfen, dann nach Deltas nochmal.
Wenn du Daten sauber taktest, wird Cutover ein Umschalten – kein Glücksspiel. Damit können wir Synapse als Pfad erstmal schließen und zum zweiten großen Universum gehen: SQL Server.
Pfad 2: SQL Server nach Fabric
SQL Server-Migrationen haben oft ein anderes Ziel: weniger „wir bauen ein neues DWH“, mehr „wir müssen aus einer gewachsenen operationalen Welt raus, ohne dass das Geschäft stehen bleibt“. Genau deshalb ist bei SQL Server die Frage nach Downtime und Parallelbetrieb so zentral.
Microsoft Fabric bietet dafür den Ansatz „Mirrored databases from SQL Server“ – also eine kontinuierliche Spiegelung in Richtung Fabric/OneLake, die dir analytische Nutzung ermöglicht, ohne sofort eine komplette ETL-Strecke zu bauen.
Wenn du diese Brücke sauber hinbekommst, gewinnst du Zeit. Und Zeit ist bei Migrationen der Rohstoff, aus dem Qualität entsteht.
Mirroring aus SQL Server: Schnell, aber nicht ohne harte Regeln
Mirroring klingt gerne nach „wir klicken das an“. In Wirklichkeit ist es ein Produktfeature mit klaren Rahmenbedingungen – und genau die musst du vorab prüfen.
Was du dir vor dem Start anschauen solltest:
High Availability-Realität: Mirroring für SQL Server ist nur auf der Primary-Datenbank einer Availability Group unterstützt; Failover-Cluster-Instanzen sind (je nach Stand) nicht unterstützt.
Konflikte mit anderen Replikationsmechanismen: Wenn die Datenbank bereits für bestimmte Link-/Mirroring-Szenarien konfiguriert ist, kann das ein Ausschlusskriterium sein.
Setup-Schritte und Berechtigungen: Die Tutorial-Schritte zeigen dir, dass das nicht nur „Item erstellen“ ist, sondern Workspace, Konfiguration und Zugriff sauber sitzen müssen.
Praktische Lessons Learned:
Netzwerk ist ein eigenes Arbeitspaket: On-prem oder abgeschottete Netze bedeuten Gateway/Firewall/Identität – plane das wie Infrastruktur, nicht wie „BI-Aufgabe“.
Betrieb mitdenken: Mirroring ist kein einmaliger Move, sondern ein laufender Prozess, den du monitoren und bei Failover-Szenarien verstehen musst.
Wenn Mirroring passt, ist es eine starke Brücke. Wenn es nicht passt, brauchst du einen zweiten Weg – und der ist weniger glamourös, dafür sehr kontrollierbar.
SQL Server nach Fabric ohne Mirroring: Snapshot-Weg
Nicht jedes System erlaubt oder verträgt Mirroring. Dann ist ein klassischer Snapshot-Ansatz oft die vernünftigste Option: exportieren, importieren, danach gezielt nachladen. Microsoft führt diesen Pfad in der Migration-Übersicht als Option über BACPAC/SqlPackage plus nachgelagerten Copy-Mechanismus.
Warum dieser Weg in Projekten oft gut funktioniert:
Du bekommst einen reproduzierbaren Prozess: Export/Import ist testbar und wiederholbar, was Dev/Test/Prod deutlich einfacher macht.
Du kannst Downtime steuern: Nicht „null Downtime“, aber planbare Fenster.
Du entkoppelst technische Hürden: Erst Schema und Grunddaten stabil, dann Deltas und Umschalten.
Der Haken: Das Zielsystem hat eigene Limitierungen. Deshalb musst du vorab prüfen, ob die Features, die du in SQL Server nutzt, in deinem Fabric-Ziel wirklich so abbildbar sind.
Dieser Snapshot-Weg ist selten der schnellste. Aber er ist oft der sauberste, wenn Governance und Wiederholbarkeit wichtiger sind als „wir sind morgen fertig“. Und genau das führt uns zum Thema, das beide Pfade verbindet: Parallelbetrieb ohne Chaos.
Parallelbetrieb ohne Kopieren: OneLake Shortcuts
Wenn du es mit der Migration nach Microsoft Fabric ernst meinst, willst du Teams nicht monatelang blockieren, bis alles umgezogen ist. Genau hier sind OneLake Shortcuts spannend: Sie erlauben, Datenquellen anzubinden, ohne alles sofort physisch zu kopieren, und machen OneLake zu einer Art virtuellem Datensee über mehrere Domains hinweg.
Was in der Praxis gut klappt:
Onboarding neuer Use Cases: Teams können schon in Fabric arbeiten, während du die große Migration noch planst.
Phasenmodell: Du migrierst erst die kritischen Datenprodukte, während andere über Shortcuts weiter nutzbar sind.
Governance-Entlastung: Du musst nicht jede Verbindung pro Engine separat aufbauen – OneLake verwaltet zentraler.
Die typische Falle: Shortcuts lösen nicht automatisch Ownership-Fragen. Wenn niemand verantwortlich ist für Änderungen, Versionierung und Freigaben, wird aus der Abkürzung schnell eine dauerhafte Baustelle.
Shortcuts helfen dir, Migration als Reise zu organisieren, nicht als Big-Bang-Event. Und sobald Teams in Fabric arbeiten, kommt die nächste Realität: Reporting-Performance und Semantic Models.
Reporting nach der Migration
Sobald du nach Fabric migrierst, willst du meist auch, dass Power BI und semantische Modelle profitieren. Direct Lake ist hier ein zentraler Baustein: Es verschiebt Datenaufbereitung nach OneLake und nutzt Fabric-Technologien wie Spark, T-SQL DML, Dataflows und Pipelines für die Prep – mit dem Ziel, Daten „lake-nah“ performant zu konsumieren.
Die „Lessons Learned“, die du nicht erst nach dem Go-Live lernen willst:
Performance hängt stark an gut getunten Delta-Tabellen: Dateistruktur, Delta Log, Anzahl/Größe der Files, Optimierung wie V-Order – das ist die Performance-Basis.
Modellqualität bleibt Modellqualität: Schlechte Kardinalitäten, wilde Beziehungen und „ich pack alles in eine Tabelle“ werden nicht durch Direct Lake geheilt.
Teste unter realer Last: Ein Report, der im Dev-Workspace schnell ist, kann unter echter Nutzung kippen – vor allem, wenn Datenupdates das Delta Log aufblasen.
Wenn du Reporting früh mitdenkst, wird Migration nach Microsoft Fabric nicht nur ein Plattformwechsel, sondern eine Qualitätssteigerung. Dann fehlt nur noch der Moment, der über deinen Projektruf entscheidet: Cutover und Validierung.
Cutover und Validierung: So wird der Umschalttag kein Nervenspiel
Cutover ist der Punkt, an dem sich zeigt, ob du migriert oder nur kopiert hast. Damit der Umschalttag ruhig bleibt, brauchst du eine klare Dramaturgie: letzte Deltas, Validierung, Umleitung, Beobachtung.
Ein praxistauglicher Cutover-Rahmen:
Freeze definieren: Was darf sich ab wann nicht mehr ändern (Schema, Jobs, Deployments)?
Letzter Delta-Lauf: Nachvollziehbar und protokolliert.
Validierungsrunde: Fachliche Checks auf KPI-Ebene, nicht nur Technik.
Umleitung der Konsumenten: Reports, APIs, Upstream/Downstream – mit klarer Rückfalloption.
Hypercare: Monitoring und schnelle Reaktionswege, besonders wenn du Mirroring oder neue Lake-Patterns nutzt.
Ein guter Cutover fühlt sich langweilig an. Und langweilig ist hier ein Kompliment. Zum Schluss ziehen wir die Essenz zusammen – als echte Lessons Learned, nicht als Folienfloskeln.
Lessons Learned: Migration nach Microsoft Fabric
Zum Schluss noch einmal auf den Punkt gebracht: Wenn du diese Punkte konsequent beachtest, vermeidest du die Überraschungen, die in Migrationsprojekten sonst erst sehr spät auffallen.
Ziel zuerst, Tool danach: Warehouse, OneLake/Lakehouse oder SQL-Zielobjekt bestimmen, dann migrieren.
Parallelbetrieb ist kein Luxus: Mirroring oder Shortcuts kaufen dir Zeit – und Zeit ist Qualität.
DACPAC/Migration Assistant ist ein Prozess, kein Event: Wiederholbarkeit schlägt Heldentum.
Limitierungen früh prüfen: Nichts ist teurer als ein Feature-Problem in der letzten Woche.
Direct Lake braucht Daten-Disziplin: Delta-Tuning ist Performance-Arbeit, nicht Kosmetik.
Validierung ist fachlich: Rowcounts sind nett, aber Business-Checks entscheiden.
Cutover ist ein Mini-Projekt: Mit Runbook, Rollen, Rückfallplan.
Wenn du diese Liste als Leitplanke nutzt, wird deine Migration nach Microsoft Fabric kein wackliger Plattformwechsel, sondern ein kontrollierter Umbau, der auch nach dem Go-Live noch stabil ist.
Der nächste sinnvolle Schritt
Eine Migration nach Microsoft Fabric entfaltet ihren Wert erst dann vollständig, wenn Architektur, Verantwortlichkeiten und Betriebsmodell sauber zusammenspielen. Genau hier entscheidet sich, ob Fabric zur tragfähigen Datenplattform wird – oder zur nächsten Zwischenlösung.
Wenn du den Einstieg in Fabric strukturiert angehen oder bestehende Setups stabil weiterentwickeln willst, unterstützen wir dich mit:
Fabric Kick Start – für einen praxisnahen Einstieg in Architektur, Zielbild und erste Use Cases
Data Strategy Check – Daten- und Analytics-Landschaft einordnen und Prioritäten setzen
Consulting Abo – für kontinuierliche Unterstützung bei Migration, Betrieb und Governance
So wird aus einer technischen Migration eine belastbare Plattform, die auch langfristig trägt.


